Vivimos inmersos en aplicaciones que utilizan la inteligencia artificial (IA) y que ―supuestamente― nos hacen la vida más fácil. De hecho, muchas veces usamos la IA sin saberlo. Cada vez que la web nos recomienda una noticia, cada vez que desbloqueamos nuestro teléfono usando la cámara que reconoce nuestro rostro o cuando las redes sociales nos recomiendan contenido, los algoritmos están haciendo su trabajo. Mediante la combinación de inteligencia artificial y machine learning, las aplicaciones “aprenden” de nuestras elecciones, registran nuestros hábitos y proyectan esos datos para sugerirnos opciones.
Y no lo hacen de manera inocua.
La inteligencia artificial muchas veces replica y profundiza los sesgos de discriminación que existen en el mundo real: desfavorecen a las mujeres y a las minorías étnicas y, en cambio, favorecen a los hombres blancos. Uno de los capítulos más sensibles se registra en las tecnologías de reconocimiento facial: las cámaras registran rostros y la inteligencia artificial tiene la capacidad para identificar a la persona y hacer diversas asociaciones. Esta tecnología es utilizada en aeropuertos, en sistemas de seguridad y, cada vez más, en la apertura de cuentas bancarias digitales o cuando una persona se registra para trabajar en servicios de la llamada “economía de las plataformas”, como Uber o Rappi.

A pesar de que su uso es más bien reciente, muchos estudios académicos ya registran un historial de errores. En los EE.UU. se denunciaron muchos casos de hombres negros arrestados después de que el reconocimiento facial los identificara falsamente como sospechosos en casos penales. En pocas palabras, es más probable que el software de reconocimiento facial cometa errores al intentar reconocer a mujeres y a personas con tonos de piel más oscuros, y que acierte con los hombres y aquellos con tonos de piel más claros.
Hace pocas semanas, un organismo de la Unión Europea publicó un borrador de regulaciones sobre el uso de inteligencia artificial que incluye algunas restricciones a las tecnologías de reconocimiento facial. Y en los EE.UU. algunas empresas de tecnología ya anunciaron que dejarán temporalmente de proporcionarles esta herramienta a las agencias de seguridad. De hecho, en 2019, San Francisco se convirtió en la primera ciudad de EE. UU. en prohibir su uso de esta tecnología por parte de las autoridades locales.
Sin embargo, uno de los países que más ha invertido recientemente en inteligencia artificial, incluida la tecnología de reconocimiento facial, es China. Ahí se implementan aplicaciones que ayudan al Gobierno a impulsar la vigilancia y ejercer control sobre la población.
TAMBIÉN PODÉS LEER


Por qué los algoritmos discriminan
El motivo es simple: no solo existe una subrepresentación de mujeres y minorías étnicas entre los desarrolladores, sino que, además, muchas veces el “entrenamiento” de estas aplicaciones no tiene en cuenta la diversidad.

Para entender el problema hay que entender primero cómo funcionan algunos algoritmos de inteligencia artificial. Cuando se habla de “entrenar” algoritmos significa que los desarrolladores les brindan millones de datos para procesar. De esta manera, los algoritmos aprenden y definen su funcionamiento. En el caso del reconocimiento facial, dependiendo de las imágenes utilizadas para el entrenamiento, el software puede (o no) incorporar sesgos que ya existen en la realidad. Hasta hace poco, por ejemplo, las búsquedas de imágenes en Google de palabras como CEO o doctor (en inglés, de género único) arrojaban resultados con una abrumadora mayoría de hombres y muy pocas mujeres.
Pero hay quienes prevén cómo resolver este problema. Generated Photos es una empresa que mediante el uso de inteligencia artificial desarrolla imágenes de rostros falsos. En un principio ofreció sus servicios como un insumo para el desarrollo de campañas de marketing y para entornos virtuales como los videojuegos. Luego descubrió que los rostros falsos —cuya falsedad es indetectable— pueden ser utilizados para entrenar otros algoritmos. Fue así que liberó un set de cientos de miles de fotos de rostros que pueden hacer ese trabajo considerando la diversidad.
¿Lo curioso? Esas imágenes son fotos de rostros falsos creados por una inteligencia artificial para entrenar a otra inteligencia artificial.
La plataforma permite elegir fotos falsas con diferentes características: edad, etnia, expresiones, género, color de ojos, color de pelo, si tiene anteojos de lectura o de sol y otro gran número de opciones. Generated Photos creó el primer set de datos tomando decenas de miles de capturas de alrededor de 70 modelos en estudios de todo el mundo. Después estuvieron meses para poder terminar de preparar la base de datos limpiando las imágenes, etiquetando los datos y organizando las fotos. Con todas las capturas listas, los desarrolladores utilizaron un sistema de inteligencia artificial para crear, a partir de esas imágenes, cientos de miles de nuevos rostros. Además, liberaron muchas de ellas en forma de código abierto para que otros las utilizaran. Esto provocó un nuevo problema: la utilización de rostros falsos para crear cuentas falsas en redes como Facebook, LinkedIn, Twitter o Instagram. ¿La posible solución o paradoja? Desarrollar una inteligencia artificial que pueda identificar un rostro falso creado por una inteligencia artificial, que a su vez fue entrenado por imágenes creadas por otra inteligencia artificial.
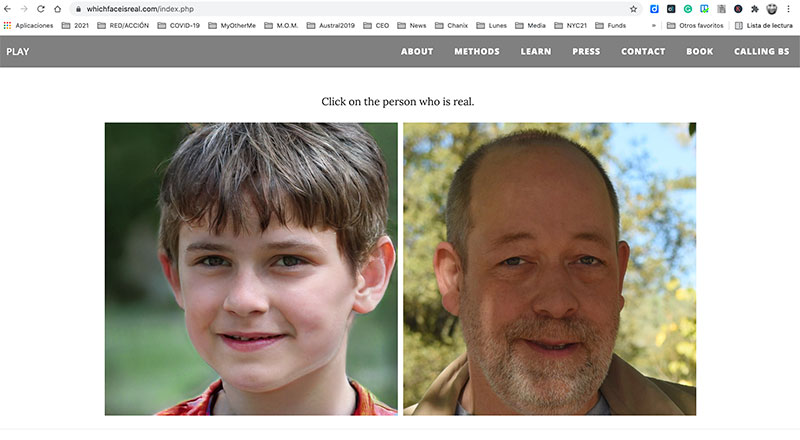
Ya existen páginas que, a modo de prueba, le preguntan a los usuarios si pueden reconocer si un rostro corresponde a una persona real o a una imagen generada por una computadora. Es el caso del experimento realizado por científicos de la Universidad de Washington, Which Face is Real, que les presenta a los usuarios dos rostros: uno creado por un algoritmo y otro real, y les pide identificar cuál es cuál. Es recomendable experimentar que, en la mayor parte de los casos, es imposible distinguir entre uno y otro.
Dilemas y límites del reconocimiento facial
Sharon Zhou, experta en inteligencia artificial de la Universidad de Stanford, al opinar sobre servicios como los de Generated Photos, explica que si bien es difícil asegurar que esto solo solucionará el problema de la falta de diversidad a la hora de entrenar algoritmos de reconocimiento facial, piensa “que puede mitigar el problema significativamente”.

Sin embargo, el investigador y candidato a doctor en machine learning para biomedicina, Martín Palazzo, no es tan optimista. “Si bien es verdad que se usan los modelos generativos para data augmentation —es decir, balancear y agrandar los set de datos— es muy delicado saber cuándo usarlos y cuándo no. Hacer data augmentation te puede ayudar a balancear tu set de datos aunque no puedas controlar el sesgo que tiene intrínsecamente el algoritmo”, explica. Pero eso no significa que no haya proyectos que valgan la pena. El problema es que todavía están en desarrollo: “El sesgo en los modelos de inteligencia artificial puede mejorar muchísimo y ya existen muchas líneas de investigación y gente trabajando en estos temas. De todos modos, esto está en etapas de investigación y poner estos sistemas y modelos en etapa de producción implica un riesgo”, agrega Palazzo.
En realidad, los sesgos discriminatorios presentes en la tecnología son un reflejo de la falta de diversidad en el mundo real y, particularmente, entre los equipos de desarrollo. Una investigación del AI Now Institute reveló que la industria del machine learning está enfrentando un “desastre de diversidad” en sus equipos. El motivo es simple: las tecnologías son desarrolladas mayormente por hombres blancos. Y si bien podemos encontrar algunas soluciones que intenten mitigar el problema, como es el caso del proyecto Generated Photos, para poder resolver este tipo de inconvenientes de raíz hay que tener equipos diversos que piensen en los usuarios en su conjunto y de la manera más inclusiva posible.
En un reciente artículo sobre este tema, Catherine Muñoz, abogada experta en regulación de sistemas de inteligencia artificial, señaló: “La inteligencia artificial, bajo una aparente objetividad, está situada en un contexto donde ha existido históricamente una brecha entre hombres y mujeres, además de la exclusión de grupos minoritarios. Por eso se diseña y desarrolla desde una perspectiva particular, de hombres blancos de élite, dado que son los que ocupan las posiciones más altas y decisivas dentro del campo de desarrollos tecnológicos”.
TAMBIÉN PODÉS LEER


El tema es tratado en el documental Sesgo Codificado, disponible en Netflix, cuyo punto de partida es la experiencia de la científica informática, Joy Buolamwini. Ella descubrió que su cara no era reconocida por un sistema de reconocimiento facial mientras desarrollaba aplicaciones en un laboratorio del Departamento de Ciencia de la Computación de su universidad. Buolamwini descubrió que los datos (caras) con los que habían entrenado a aquel tipo de sistemas eran principalmente de hombres blancos. Esto explicaba por qué el sistema no reconocía su cara afroamericana.
***
Esta nota forma parte de la plataforma Soluciones para América Latina, una alianza entre INFOBAE y RED/ACCIÓN, y fue publicada originalmente el 11 de junio de 2021.
Podés leer este contenido gracias a cientos de lectores que con su apoyo mensual sostienen nuestro periodismo humano ✊. Bancá un periodismo abierto, participativo y constructivo: sumate como miembro co-responsable.